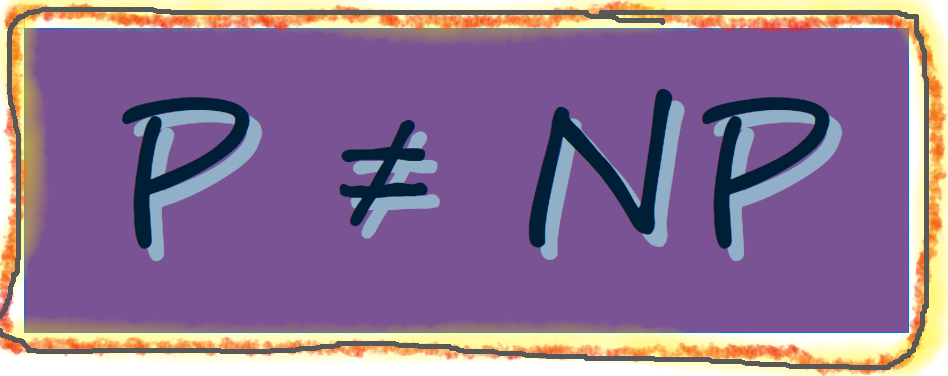I am rereading rereading Robert Goldblatt’s book, Topoi, though in many respects it seems like I’m reading it for the first time. When there is enough time and space between myself and some volume or other, that experience of ‘(re)reading it for the first time’ is not all that uncommon. It occurred not too long ago with E.P. Thompson’s The Making of The English Working Class, and Durrell’s Alexandria Quartet. Those works both had in the neighborhood of forty years between the first and the second readings, so I feel less guilty at the sense of surprise and pleasure. With Topoi, my excuses are somewhat more thin, though I can still assert with considerable truth and honesty that there’s been considerable intellectual development on my part since the first time I tackled the book. I mention this not just to make what amounts to little more than a peculiar Facebook post (some people share pictures of their meal, after all), but to set up a discussion of why a Whiteheadian should pay special attention to that area of abstract algebraic thinking known as Category Theory. I’ll first spend a few words talking about the book itself.
The word “topoi” is the plural form of “topos,” which seems rather more elegant than saying “toposes.” A topos is a category theoretic structure that is rich in a variety of “nice” formal characteristics, the details of which I’ll spare you (as that would require an entire book on category theory to explain.) Now, a category (such as might take on the structural features that would further specify it to be a topos) is a mathematical constructions that turns away from “objects” so-called to devote particular attention to functions, transformations, and operations without any special concern for the supposed “what” that is being transformed or operated on. As such, category theory is arguably the purest form of algebraic thinking around. It is scarcely an accident that Leo Corry’s magnificent history of the development of abstract algebra, Modern Algebra and the Rise of Mathematical Structures, ends with the emergence of category theory.
There is a certain group of scholars – I’ll name no names – which has taken on such a dominant position in Whitehead scholarship (at least, within the US), that one could arguably characterize their position as “hegemonic.” I have personally met a number of individuals associated with this group, whom I’ll simply call “The Group,” and freely admit that they are, as individuals, fine, generous, and altogether excellent folks. My complaint here – and I will be complaining rather sharply – is not with any of them as particular persons, but rather with the hegemonic direction in which The Group has taken Whitehead scholarship. That direction is what I am calling “Happy-Fluffy-Touchy-Feely-God-Talk” (HFTFGT from now on.)
Now, there is no question that Whitehead spoke of “God” extensively in his writings. Many people have the devil’s own time with such talk, those whom I’ll often characterize as “Ouchie Atheists,” for whom any such discussion drives them either into a fury or else into something like a cognitive anaphylactic shock. (Sometimes both.) This is one of the lesser pities of our day and age, a consequence of neo-fascist Christian Dominionist fundamentalists having hijacked the word and all discussions thereof. It is additionally unfortunate with regard to Whitehead scholarship because his use of the “G-word” could easily be replaced throughout his text with the Greek word “arché,” which would eliminate at a stroke the difficulties the Ouchie Atheists have and (arguably, at least) make it possible for them to dive more deeply into Whitehead’s texts and arguments. But Whitehead was intransigent in his refusal to employ non-English words. “Atom” was an exception. Though it originated with the Greeks, it had by his time – both by convention and courtesy – been thoroughly adopted as “English.” This is a little ironic, since contrary to most physicists of his day, Whitehead continued to use it in the original Greek sense of “a-tomos,” meaning “uncut.” So an atom for Whitehead was not a microscopic corpuscle, but an undivided whole which could be of any size.
I like the word “arché” because it can be translated as “foundation/font,” and this is what Whitehead meant by “God”: the rational foundation of reality, and the font of creativity. (This latter is one of the things that distinguishes process philosophies from static, substance based ones: the universe is a process of creative advance.) Notice that I do not suggest the Greek word for “god,” “theos” (or possibly “theou,” my Greek is not very good.) This is a deliberate choice, readily justifiable by even a moderately close reading of what Whitehead actually says, particularly within the pages of his masterwork of metaphysics, Process and Reality (PR).
With, however, the exception of one sentence.
This sentence appears in the last few pages of PR, which are separated from the rest of the volume as Part V. The language and argument of this final, very short “part” is fundamentally different from the preceding hundreds-plus pages of text, and this radical difference has led some to wonder just how genuinely integral an element of the rest of the discussion it truly is. In these final, very few pages, Whitehead allows himself to slip into more poetic language, most particularly with the above mentioned one sentence – which I’ll not quote. (If you know, you know, and if you don’t you’ll recognize it instantly should you ever read PR to the end.) But members of The Group, and others sympathetic to their program, latched onto that one sentence and ran with it. They ran fast, long, and hard, and are still running. From this we get the HFTFGT of process theology.
And it has swallowed the scholarship whole. So much so that Whitehead’s triptych of 1919 – 1922 (Enquiry into The Principles of Natural Knowledge, The Concept of Nature, and The Principle of Relativity with Applications), a revolutionary re-evaluation of the entire philosophy of nature, have largely vanished from the canon of Whitehead’s works that are studied. (Let me reiterate that this is within the US. Chinese scholars, for example, recently celebrated the centennial of those works with no fewer than three separate conferences, one for each book.)
Even those works of Whitehead’s that do receive some attention receive it only selectively. Thus part IV of PR, for example, is often skipped over and ignored with students sometimes being told to ignore it because it is “irrelevant.” One might, alternatively, point out that part IV is the beating heart of Whitehead’s entire relational system, where he presents his mature mereotopology, his non-metrical theory of curvature (“flat loci”), his subtle theory of physical connectedness and causality (“strains”), his completed theory on the internalization of relatedness as the flipside to the theory of the externalization of relatedness found in part III, etc. But part IV also involves a lot of logical and mathematical thinking “stuff,” and so one can just skip over that because it doesn’t feed into HFTFGT. A more cautious reader might suspect that what this rather demonstrates is that it is HFTFGT that is flopping around looking for relevance. But such cautious readers are not being invited into the club, and their professors are not encouraging their students to adopt such cautious approaches.
It is partly as a result of this narrow and eminently disputable presentation of Whitehead’s philosophy that many outside the field who might otherwise profit from engaging with Whitehead’s ideas (especially persons in the sciences), explicitly reject the notion out of hand. Because, after all, Whitehead is “nothing more than” a lot of HFTFGT. And people “just know this to be the case” because they are constantly and loudly reminded of this “fact” by those experts who are only interested in HFTFGT.
(Of course, persons in the physical sciences tend to reject any suggestion of engaging in philosophy because it is, after all, philosophy. They often do this as they explicitly engage in philosophical discourse; and do so badly.)
Such a reductionist caricature of Whitehead’s thought is, of course, the worst sort grotesquely fatuous twaddle imaginable. Let me repeat, Whitehead wholly re-imagines Nature in a relationally robust and holistic framework that is original, insightful, and logically rigorous. But consider in comparison what your grasp of Christianity might be were it the case that all you ever heard about it came from the neo-fascist Christian Dominionist fundamentalists. Your idea of Christ would look more like Adolf Hitler. (By the bye, in contrast to the neo-fascists, the advocates of HFTFGT promote a vastly more Christ-inspired vision of God and the gospels that is genuinely loving and caring for ALL of creation.) And so it becomes increasingly difficult to even suggest to people who are not already heavily, even exclusively, invested in HFTFGT to cast even a casual eye on Whitehead’s work.
Which brings us to the matter of how a vine can kill a tree.
There is a method of killing a tree called “girdling.” A tree grows out as well as up. But if something is tightly bound around the outside of the trunk (it is “girdled”) the tree can no longer grow outwards. And it is these outer portions that carry the nutrients up the trunk to the rest of the tree. So the effect is like a garrote.
A vine is capable of girdling a tree. There is no malevolence involved, no ill or predatory intent; but the effect is the same. This is what ‘The Group’ is doing, I would argue, to the larger tree of Whitehead scholarship. (One of the ironies here is that they themselves are being girdled by the neo-fascist Christian Dominionist fundamentalists, who deny that liberal – never mind process – theology even qualifies as Christianity, or as anything other than the work of the Devil, even though this form of “devilry” is demonstrably truer to the Gospels. But just try to find someone who is not already an expert in the field who is even aware of the existence of process theology.)
I don’t want the HFTHGT people to go away, but I would like to see a serious effort on their part to acknowledge that their project emerges from a vanishingly small corner of Whitehead’s work. I don’t want to chop down the vine, but I would like the vine to stop strangling the tree. This would include exercising some genuine circumspection about what they attribute to Whitehead, as opposed to what they themselves rather freely speculate about, far beyond anything he – in his meticulous, mathematically rigorous and disciplined way – ever pretended to entertain.
The guiding motto in the life of every natural philosopher should be, Seek simplicity and distrust it.”
– Alfred North Whitehead, The Concept of Nature (end of chapter VII.)
Ultimately, the only way we know how to measure the complexity of some process or phenomenon – beyond excruciatingly vague and unhelpful statements like, “this is really complicated” – is by measuring how hard it is to solve the mathematical equations used to characterize the problem. All the rest, even when palpably, indisputably true, is just hand-waving. Sometimes hand-waving makes us feel better, because we need to burn off the energy pent up in our frustration. But it never really tells us anything. On the other hand, we really do have some effective means of measuring how hard it is to solve some mathematical equation or other, and we’ve refined such measures significantly over the past fifty years because such measures tell us a great deal about what we can and cannot do with our beloved computers (which includes all of your portable and handheld devices, in case you weren’t sure.)
Some problems simply cannot be solved. This even despite the fact that the problems in question seem perfectly reasonable ones that are well and clearly formulated. (Actually, being well formulated makes it easier to demonstrate when a problem cannot be solved.) Some problems can be solved, albeit with certain qualifications, while still others are “simply” and demonstrably solvable.i However, saying that a problem is “solvable” – even in the pure and “simple” sense (notice how I keep scare-quoting that word) – doesn’t mean that it can be solved in any useful or practical sense. If the actual computation of a solution ultimately demands more time &/or computer memory space than exists or is possible within the physical universe, then it is unclear how we mere mortals benefit from this theoretical solvability.ii It is these latter considerations that bring us into the realm of computational complexity.
Anyone who is reading this post – indeed, anyone who can read at all – has some minimal exposure to mathematical ideas, even if that exposure goes no further than elementary arithmetic and not, as I am only half-jokingly known to say, actual mathematics. (Well, since I’ve mentioned it: the thing I’m known to say is, “that’s not mathematics, that’s arithmetic.” This is always in response to someone who has protested something along the lines, “I’m no good at mathematics; I can’t even balance my checkbook.” The humorous, yet legitimately educative nature of MY statement always strikes me as obvious, yet I am constantly amazed by the numbers of people who get lost in the elementary rhetoric of my statement.)
In any event, even such minimal exposure is typically enough to satisfy most people, even most mathematicians (I suspect), that they have a pretty good handle on what that equals sign (“=”) means as it is expressed in, say, the title of this little essay. Clearly I wouldn’t be writing about it if such an impression was even remotely true. For one thing, how do we read “A = B”? Does it say, “A equals B”, or does it say “A is B”, and is there a difference between those two? Spoiler: yes. Yes to both questions, depending on how crudely one is using one’s language, which makes the fact that “equals” does not equal “is” an especially problematic conflation of terms. “Is” tends to mean “identity” in such a context, which is tricky enough in its own right (I wrote an MA thesis on the subject). The reading of “=” as “equals” helps to emphasize a somewhat more functional approach to matters, though it is still more rigid and “substantive” than such formal notions as “equivalence” and “isomorphism.” topics I’ll likely blog about in the future because I can already hear the math-phobes screaming in horror. For now, I want to focus on the logical issues of “equals,” as a formal relation. Thus, the word “equality” may also find a use here, but that use should not be mistaken for the political, economic, cultural, &/or social senses of the term. (On the other hand, I do not preclude in advance that what I say here will have no bearing on those uses, either.) Obviously, the starting point for the primary discussion is with the work of Alfred North Whitehead. Continue reading →
“The Quantum of Explanation advances a bold new theory of how explanation ought to be understood in philosophical and cosmological inquiries. Using a complete interpretation of Alfred North Whitehead’s philosophical and mathematical writings and an interpretive structure that is essentially new, Auxier and Herstein argue that Whitehead has never been properly understood, nor has the depth and breadth of his contribution to the human search for knowledge been assimilated by his successors. This important book effectively applies Whitehead’s philosophy to problems in the interpretation of science, empirical knowledge, and nature. It develops a new account of philosophical naturalism that will contribute to the current naturalism debate in both Analytic and Continental philosophy. Auxier and Herstein also draw attention to some of the most important differences between the process theology tradition and Whitehead’s thought, arguing in favor of a Whiteheadian naturalism that is more or less independent of theological concerns. This book offers a clear and comprehensive introduction to Whitehead’s philosophy and is an essential resource for students and scholars interested in American philosophy, the philosophy of mathematics and physics, and issues associated with naturalism, explanation and radical empiricism.”
It is certainly disturbing to see how many people prefer a convenient lie over a disquieting truth. But more importantly, we should make note of how many people will flee in abject terror to the warm, terroristic embrace of a convenient lie when confronted with an indisputable uncertainty, the unavoidable knowing that you do not know. I should get that tattooed somewhere … somewhere where no one will ever see it …
There is a formal structure to at least some kinds of disruptive uncertainty, and that structure is not all that hard to understand. I’ll mostly be discussing that logical structure, which often requires a kind of patience with inconsistency. But I will turn to the psychological issues of those who embrace inconsistency without thought at the end. What I wish to address here are kinds of inconsistency, most importantly noting that there are genuinely and importantly different kinds. I’ll mainly draw on investigations by Nicholas Rescher and Robert Brandom, coupled with developments by Jon Barwise and John Perry. Continue reading →
So my last round of musing was on the subject of “emptiness.” Connected to that idea is the concept of “fullness,” of “plenum.” I suspect that one of the primary failures of contemporary metaphysics is misunderstanding which is really which: that is to say, what is really full, and what is really empty. Here again, Whitehead’s process metaphysics offers us important insights. Because how we think of “fullness” – of a thing, a region of space, or whatever – is directly correlated to what we believe to be genuinely real. I argued earlier against the naïve concept of “empty” space, pointing out that not only is that space (according to physics) a broiling froth of micro events and virtual particles, but that it is also densely awash in relational connections to the rest of the universe. Adding to that earlier discussion, one could say that the space itself is a kind of “thing”: it is an event in its own right, it is a process of space relating itself to other spatial events. In this regard, Whitehead rejected the “material aether” that dominated astrophysical thought in the days between James Clerk Maxwell and Albert Einstein (the last quarter of the 19th C. to the first decade or two of the 20th), and argued instead for an “aether of events” as the dominating characteristic of space.
Without assuming – indeed, explicitly denying – any absolute sense of either “emptiness” or “fullness,” what sorts of relative conditions might lead us to characterize one sort of collection as generally more full, and another as comparatively more empty? Well, for that we need a notion of what it is that fills, hence that which is not there when things are empty. My argument is that what “fills” are events and relations. Continue reading →
So, what is it that makes something true? (Trust me, this ties in with this post’s title.) If I say that “X is the case,” and it, indeed, turns out that X IS the case, then my saying so was true. Or, rather, the thing I said was true, and my saying it was said truly. (Actually, my saying it was said truly, because I truly said it, regardless of whether what I said was actually true.) But what establishes the connection(s) between my saying it is the case, and its actually being the case? Well, presumably it is reality that makes that establishment; but how is that reality, how is that establishment, established in experience such that the truth-saying and the truth-being converge in a truth making?
Because even as (and insofar) as “the truth is out there,” our having, getting, finding, or whatever, that truth involves a substantial amount of making. If you take the idea of truth seriously, then you must take seriously the fact that we have to go out and make that truth apparent through significant and substantive inquiry. Where this is going (and it will go fast) is that the maker that connects the truth as said with the truth as found, looks a lot like a successful “strategy” in a “game.” This is a formal, logical concept, which brings scientific inquiry into a dirty-dance with that part of formal logic known as model-theory. (Somewhere, somebody has sheet music on this stuff … ) Continue reading →