
The guiding motto in the life of every natural philosopher should be, Seek simplicity and distrust it.”
– Alfred North Whitehead, The Concept of Nature (end of chapter VII.)
Ultimately, the only way we know how to measure the complexity of some process or phenomenon – beyond excruciatingly vague and unhelpful statements like, “this is really complicated” – is by measuring how hard it is to solve the mathematical equations used to characterize the problem. All the rest, even when palpably, indisputably true, is just hand-waving. Sometimes hand-waving makes us feel better, because we need to burn off the energy pent up in our frustration. But it never really tells us anything. On the other hand, we really do have some effective means of measuring how hard it is to solve some mathematical equation or other, and we’ve refined such measures significantly over the past fifty years because such measures tell us a great deal about what we can and cannot do with our beloved computers (which includes all of your portable and handheld devices, in case you weren’t sure.)
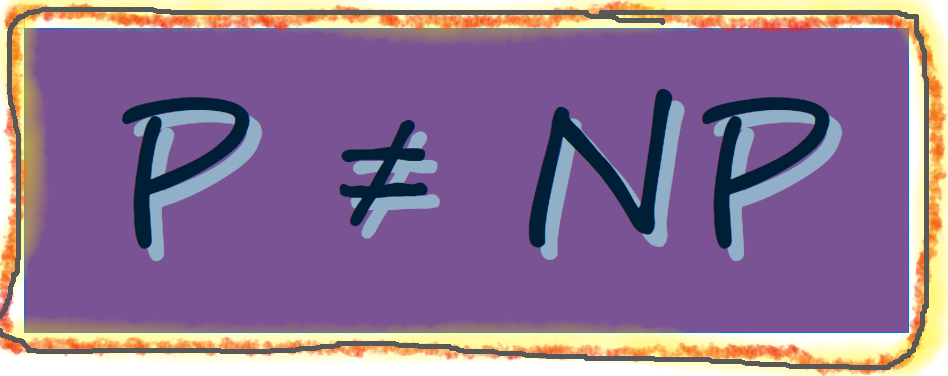
Some problems simply cannot be solved. This even despite the fact that the problems in question seem perfectly reasonable ones that are well and clearly formulated. (Actually, being well formulated makes it easier to demonstrate when a problem cannot be solved.) Some problems can be solved, albeit with certain qualifications, while still others are “simply” and demonstrably solvable.i However, saying that a problem is “solvable” – even in the pure and “simple” sense (notice how I keep scare-quoting that word) – doesn’t mean that it can be solved in any useful or practical sense. If the actual computation of a solution ultimately demands more time &/or computer memory space than exists or is possible within the physical universe, then it is unclear how we mere mortals benefit from this theoretical solvability.ii It is these latter considerations that bring us into the realm of computational complexity.
